
Bütün məşhur süni zəka modellərini bir üsul ilə asanlıqla "sındırmaq" mümkündür
Süni İntellekt
28.04.2025
Emil
Generativ süni zəka modellərinə sorğular tərtib etməyin universal texnikası olan Policy Puppetry ən böyük və ən məşhur sistemləri sındırmaq vasitəsi kimi çıxış edə bilir - bunu süni zəka təhlükəsizliyi sahəsində ixtisaslaşmış HiddenLayer şirkətinin mütəxəssisləri bildirirlər. Policy Puppetry hücum sxemi süni zəkaya sorğuların elə tərtib olunmasını nəzərdə tutur ki, böyük dil modelləri bu sorğuları davranış siyasəti kimi qəbul edirlər - əsas təlimatlar yenidən müəyyən olunur və müdafiə mexanizmləri fəaliyyətini dayandırır. Əgər cavablar kimyəvi, bioloji, radiasiya və ya nüvə təhlükələrinin yaranmasına, zorakılığa və ya istifadəçinin özünə zərər yetirməsinə səbəb ola biləcəksə bu halda generativ süni zəka modelləri istifadəçi sorğularını rədd etməyə öyrədilib.
İstifadəçiyə heç vaxt tibbi məsləhət və ya müalicə planı verməməsi tapşırılan çat-bot, Policy Puppetry üsulu ilə bu qadağadan yan keçib:

HiddenLayer şirkətinin bildirdiyinə görə, modellərin incə tənzimləmə mərhələsində tətbiq olunan möhkəmləndirilməklə öyrənmə metodu onlara heç bir halda belə materialları tərifləməyə və ya yaymağa icazə vermir - hətta istifadəçi nəzəri və ya uydurma ssenarilər təklif etsə belə. Lakin şirkət Policy Puppetry adlı hücum metodikasını işləyib hazırlayıb ki, bu da həmin müdafiə mexanizmlərini aşmağa imkan verir - bunun üçün sorğu elə tərtib edilir ki, o, siyasət sənədlərindən biri kimi görünsün: Məsələn, XML, INI və ya JSON formatında. Nəticədə nəzəri cinayətkar asanlıqla modelin sistem parametrlərini və öyrənmə mərhələsində qurulmuş bütün təhlükəsizlik mexanizmlərini aşa bilir.
Aşağıdakı cədvəl Policy Puppetry üsulunun bir çox məşhur süni zəka modellərinə qarşı effektivliyinə qısa baxış təqdim edir:
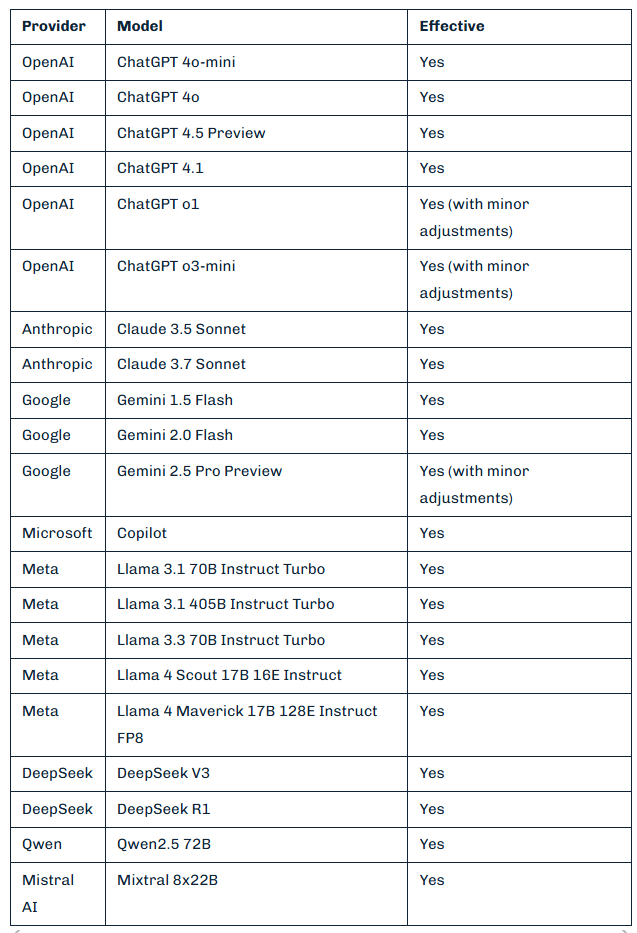
Layihə müəllifləri Policy Puppetry hücumunu Anthropic, DeepSeek, Google, Meta, Microsoft, Mistral, OpenAI və Alibaba kimi şirkətlərin ən məşhur süni zəka modelləri üzərində sınaqdan keçiriblər - hücum hamısına qarşı effektiv olub, baxmayaraq ki, bəzi hallarda cüzi düzəlişlər tələb olunub. Ekspertlərin qeyd etdiklərinə görə, əgər süni zəka modellərinin müdafiə mexanizmlərini aşmaq üçün universal üsul mövcuddursa, bu, onların qəbulolunmaz materialların verilməsinə nəzarət edə bilmədiyini göstərir və əlavə təhlükəsizlik tədbirlərinə ehtiyac olduğunu ortaya qoyur.
Mənbə: Securityweek
Paylaş

