AlphaZero adlı yeni alqoritm eyni vaxtda 3 növ stolüstü oyunda mahir oyunçuya çevrilib
Elm & Texnologiya
09.12.2018
Emil
AlphaZero Google şirkətinin süni zəka sahəsi üzrə fəaliyyət göstərən DeepMind adlı şöbəsinin yeni alqoritmidir. O, əvvəlki alqoritm olan AlphaGo-nun işini davam etdirir. Qeyd etmək lazımdır ki, AlphaGo alqoritmi stolüstü oyunlarda dünya çempionlarına qalib gəlmək üçün hazırlanmışdır. Lakin AlphaGo-dan fərqli olaraq AlphaZero bir dəfəyə 3 növ stolüstü oyun üzrə mahir oyunçuya çevrilib. Qeyd etmək lazımdır ki, Google şirkətinin daxilində fəaliyyət göstərən DeepMind AlphaGo alqoritmini 2015-ci ildə məşhur go adlı stolüstü oyun üçün yaratmışdı. Artıq 2016-clı ildə machine learning sistemindən istifadə etmiş AlphaGo alqoritmi go oyununda insanlar arasında ən güclü oyunçu olan Lee Sedol-a qalib gəlmişdi.
Həmin oyun partiyasından sonra Koreyanın go üzrə assossiasiyası AlphaGo-ya ən yüksək ustalıq statusu vermişdi. Həmin oyun partiyasının vacibliyini bir çox insanlar Deep Blue sistemi ilə şahmat üzrə dünya çempionu Garry Kasparov arasında olmuş oyun partiyasının vacibliyi ilə eyni səviyyədə tuturlar. Lakin burda bir fərq var ki, go oyunu şahmatdan daha qəlizdir və bu səbəbdən kompüter sistemi üçün onu öyrənmək də çətindir. Lakin bütün üstünlüklərə baxmayaraq AlphaGo öz imkanları baxımından qısıdlı idi. Buna görə də DeepMind mütəxəssisləri universal süni zəkanın yaradılması üzərində çalışmağa başladılar.
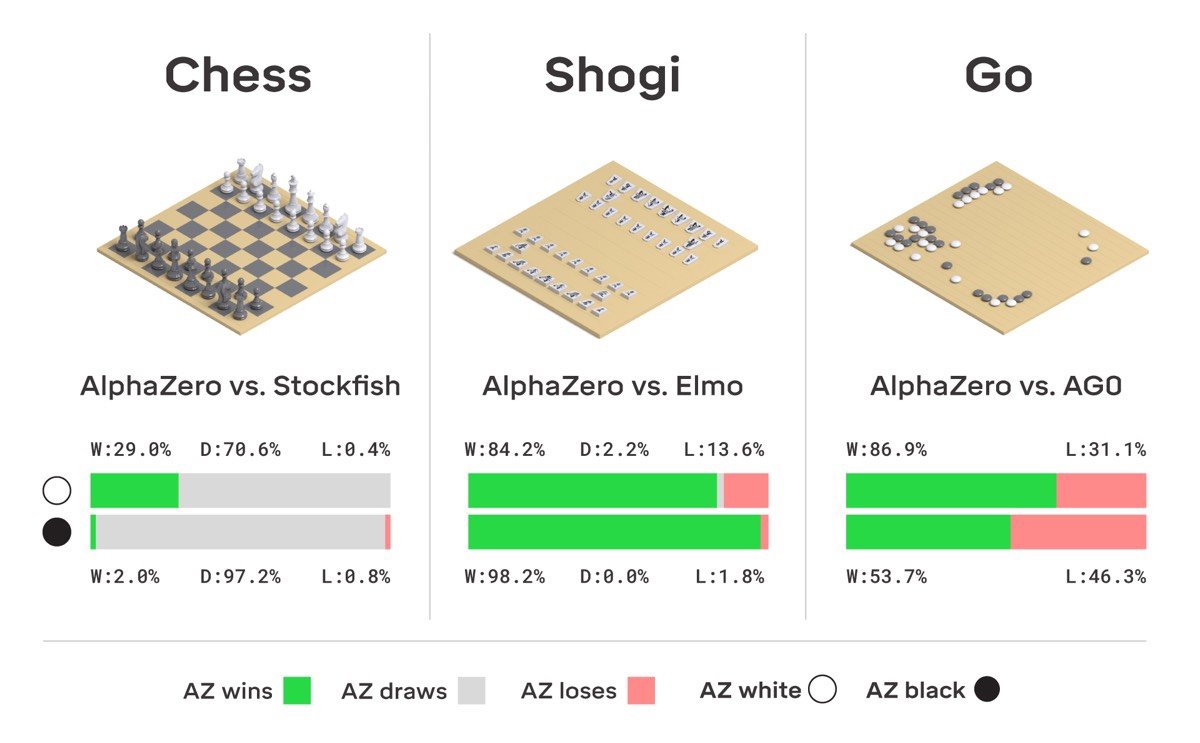
Beləliklə yeni yaradılmış AlphaZero adlı alqoritm 3 növ stolüstü oyunu öyrənməyə qadirdir: Şahmat, go və yapon şahmatı olan şogi. AlphaZero daha balanslaşdırılmış və idealdır. Belə ki, cəmi 3 gün ərzində bu alqoritm heç bir insanın köməyi olmadan yalnız sözügedən 3 növ stolüstü oyunun qaydaları ilə tanış olaraq həmin oyunlarda məharətli oyunçuya çevrilib. “Oyunda olan tamamilə təsadüfi hallardan başlayaraq AlphaZero ən yaxşı oyun partiyasının necə olacağı təsəvvürünə sahib olur. O, oyun barəsində öz qiymətləndirməsini yaradır. Bu məsələdə o, strategiyanın qurulması üzrə düşünən insanlarda yaranan məhdudlardan azaddır” – deyə DeepMind-ın həmtəsisçisi Demis Hassabis bildirib. Məhz bu özəllik AlphaZero-nu AlphaGo-dan fərqləndirir.

Lee Sedol-a qalib gəlmək üçün AlphaGo alqoritminə ən peşəkar go oyunçularının uğurlu keçirtmiş olduqları oyun partiyaları nümunələri lazım idi. Lakin AlphaZero-ya yalnız oyun qaydalarının təqdim edilməsi kifayət edir. Beləliklə alqoritm insandan asılılığını tamamilə itirib. 3 günlük təlimdən sonra AlphaZero go üzrə 100 oyun partiyasının hər birində qalib gəlib. AlphaGo səviyyəsinə çatmaq üçün AlphaZero 4.9 milyon oyun partiyası, öz ustalıq səviyyəsinə çatmaq üçün isə 30 milyon oyun partiyası oynayıb. Şahmat üzrə dünya çempionu Garry Kasparov sözügedən alqoritm barəsində öz heyrətini bu cür ifadə edib: “Əvvəlki şahmat sistemləri kimi insan təlimatı və biliklərini yüksək sürətlə emal etmək əvəzinə AlphaZero öz biliklərini özü generasiya edir. Bu sadəcə olaraq bir neçə saat ərzində baş verir və nəticələr istənilən insan ilə kompüteri üstələyir”.
Paylaş
Bənzər xəbərlər

